
Prêt pour mettre en place l’orientation automatique des demandes avec JSM ? C’est parti !
Dans un article précédent, je vous ai présenté le contexte de la mise en place de plusieurs projets d’assistance technique et métier avec Jira Service Management (JSM) chez un client. Nous avions abordé :
- L’organisation des trois équipes d’assistance et les difficultés rencontrées pour l’élaboration des projets ;
- La solution adoptée pour répondre au contexte de mon client (un socle commun personnalisable et extensible) ;
- Différents conseils si vous êtes dans un cas similaire.
Dans les prochains articles, je vous présente la mise en œuvre concrète de certains éléments clés de la solution choisie dans JSM. Et nous allons commencer avec une étape très importante dans le cycle de vie d’un ticket : son orientation automatique vers les bonnes personnes, première partie (comme au cinéma 🤓 il faut attendre pour avoir la suite).
Il est maintenant temps de mettre les mains sous le capot !
Disclaimer
Premièrement, la solution présentée ci-dessous et proposée au client n’est pas LA seule et unique solution possible.

Crédit photo
Il s’agit d’une façon parmi tant d’autres de répondre au besoin, et surtout, aux différentes contraintes de mon client. Elle est complètement liée à son contexte. La façon dont les utilisateurs appréhendaient un outil comme Jira, l’écosystème des applications déjà en place, les contraintes de sécurité, etc.
Ensuite, elle a été construite au fur et à mesure. Tous les éléments n’ont pas été mis en production en une seule fois. La mise en place d’améliorations au fil de l’émergence de certains besoins a permis d’éviter de construire une usine à gaz pleine de fonctionnalités inutiles.
Cet article n’est pas un tutoriel « pas à pas » pour réaliser le paramétrage présenté.
Enfin, la solution présentée a été apportée sur une instance Jira Data Center, avec Jira Software et Jira Service Management en version minimum 8.13. L’instance dispose de différents plugins ayant permis de mettre en place certaines mécaniques ou automatisations :
- Script Runner, un plugin payant qui permet de personnaliser Jira à l’aide de script écrit dans le langage Groovy. Des scripts pré-écrits sont livrés avec le plugin mais il convient d’avoir un minimum de connaissances en développement pour pouvoir en exploiter toute sa puissance ;
- Automation for Jira (inclus dans Jira Software et Jira Service Management Data Center). Automation for Jira permet de construire des règles automatiques facilement et visuellement, sur un format de « when, if, then » ;
- Assets – ex Insight (inclus à partir de la version 4.15 de Jira Service Management Data Center). Assets, que vous trouverez sous le nom de Actifs en français, est le module de référentiels de Jira. Il permet de définir, structurer et gérer des référentiels de données, utilisables ensuite dans les tickets.
Let’s go !
Dans la suite de l’article, nous appellerons les personnes prenant en charge et traitant les demandes d’assistance des agents. Pour des raisons d’anonymisation, les noms des agents, équipes, et services ont été modifiés.
Le principe de l’orientation automatique : poser les bases
L’une des priorités des différentes équipes d’assistance était d’orienter automatiquement une demande vers les bonnes personnes dès sa création, sans avoir à passer par un premier « sas » de qualification. Pour réussir cela, il a donc fallu :
- Bien comprendre comment sont organisés et regroupés les agents ainsi que leurs périmètres d’intervention ;
- Permettre à l’utilisateur de pré-qualifier en autonomie sa demande, en renseignant directement les informations nécessaires dans sa demande ;
- Mettre en place une table de routage pour décrire les combinaisons de critères et quels agents elles concernent dans les équipes d’assistance.
La modélisation des cellules d’assistance
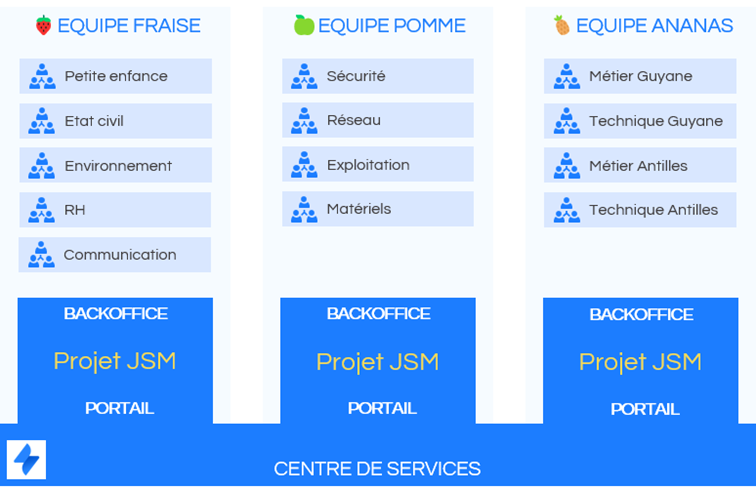
En échangeant avec les trois équipes d’assistance, nous avons pu observer à chaque fois un regroupement des agents par domaine d’expertise métier ou technique. Ces groupes ont été nommés « cellules d’assistance ».
Chaque cellule d’assistance a la responsabilité de traiter les demandes portant sur un périmètre donné. Mais il faut aussi prendre en compte que chacune a ses préférences de gestion.
Il faut donc représenter cette notion dans Jira, avec la possibilité de gérer les spécificités de certaines cellules. Il ne faut pas non plus oublier que nous avons trois équipes d’assistance distinctes, qui ont un mode de travail légèrement différent.
Le choix final s’est porté sur la mise en place d’un référentiel des cellules d’assistance grâce à Assets.
Action 1 – Création d’un référentiel des cellules d’assistance dans Assets
En prérequis, vous devez avoir créé un schéma d’objets dans Assets.
Un ou plusieurs schéma d’objets ?
Initialement, nous avions choisi de réunir les objets autour de l’assistance dans un schéma dédié. Aujourd’hui, nous songeons à migrer ces objets dans un schéma plus global regroupant les applications, les services et les processus, car ils partagent tous des notions communes et sont fortement liés.
Il n’y a pas de bonne ou mauvaise pratique à mon sens. Choisissez ce qui vous parait être le plus cohérent, en terme de gestion, d’autorisations, et de liens entre les objets.
Pour bénéficier d’une structure commune entre chaque équipe tout en ayant la possibilité d’étendre les attributs d’une équipe donnée, nous allons exploiter la fonctionnalité d’héritage d’Assets.
L’héritage consiste tout simplement à créer un type d’objet parent dans votre schéma d’objets, puis des types d’objets enfants qui vont hériter des attributs de ce dernier. Le parent porte donc les attributs communs à tous les types enfants.
Il est ensuite possible d’ajouter des attributs complémentaires et indépendants à chaque type d’objet enfant.
Notre type d’objet parent n’ayant pas vocation à représenter des objets directement, nous le rendons abstrait. Cela signifie qu’il n’est pas possible de créer des objets directement au niveau parent.
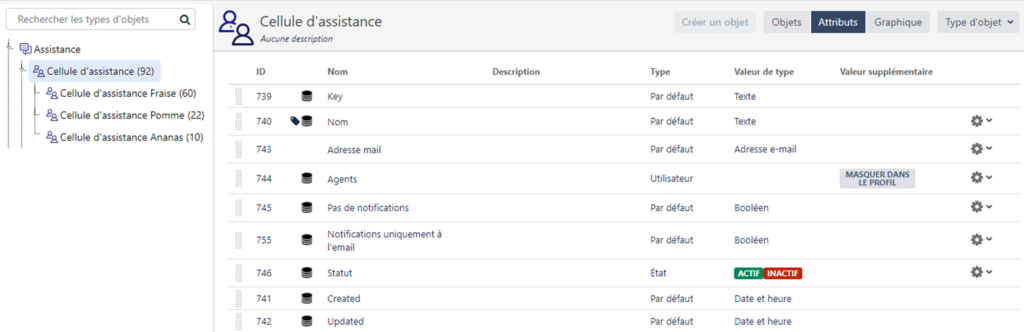
Nous créons donc un premier type d’objet parent Cellule d’assistance, qui porte tous les attributs communs à toutes les cellules des trois équipes :
- Un nom
- Un statut
- La liste des agents qui composent la cellule
- Une adresse email générique
- La possibilité de désactiver les notifications pour la cellule
- Le mode de notification (uniquement l’adresse email générique, uniquement les agents, les deux)
Nous ajoutons ensuite trois types d’objets enfants représentant les spécificités des cellules de chacune de nos trois équipes d’assistance : Cellule d’assistance Fraise, Cellule d’assistance Pomme et Cellule d’assistance Ananas.
L’équipe Fraise a besoin d’indiquer à quelle Direction chaque cellule est rattachée. Côté équipe Ananas, ils souhaitent identifier pour quelle région du monde chaque cellule intervient. Nous ajoutons donc des attributs complémentaires à ces deux équipes.
Les avantages et inconvénients de l’héritage dans Assets
➕ On aime bien :
- L’ensemble des objets enfants est consultable depuis le type parent directement ;
- La configuration des éléments communs n’est à faire qu’une seule fois ;
- Il est ensuite facile de réaliser des recherches directement à partir du type parent ;
- Techniquement, l’identifiant des attributs est identique pour chaque enfant, ce qui est très pratique lors de l’écriture de scripts.
➖ On aime moins :
- Tous les enfants doivent hériter obligatoirement de tous les attributs parents ;
- Les attributs parents sont affichés en premier, il n’est pas possible dans l’ordre d’affichage de positionner un attribut spécifique à un enfant au milieu des attributs parents, ce qui rend parfois la lisibilité des formulaires de création / modification difficile ;
- Quand on a choisi de commencer avec l’héritage (ou sans), il est très compliqué de revenir en arrière.
Nous avons maintenant un référentiel qui regroupe toutes nos cellules d’assistance par équipe. Voici le résultat que nous avons obtenu :
La définition du catalogue de services
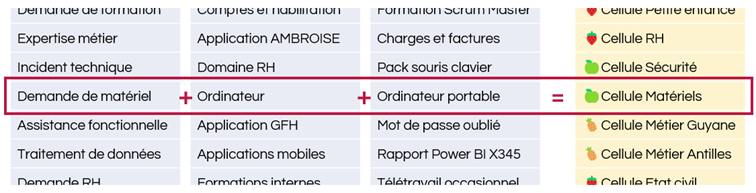
Après avoir identifié les différentes cellules d’assistance, il nous faut construire notre catalogue de services, c’est-à-dire la liste de tous les services proposés par chaque cellule d’assistance aux utilisateurs.
Mais qu’est-ce qu’un service ?

Il n’y a pas de réponse simple et universelle. Un service peut prendre différentes définitions selon l’entreprise ou l’organisation, son contexte, son métier. Et parfois même selon l’équipe d’assistance. Dans notre cas, nous avons dû trouver une définition commune aux trois équipes d’assistance, mais extensible. Et c’est naturellement que ce catalogue a pris sa place dans Assets, au côté des cellules d’assistance.
Action 2 – Création d’un catalogue de services dans Assets
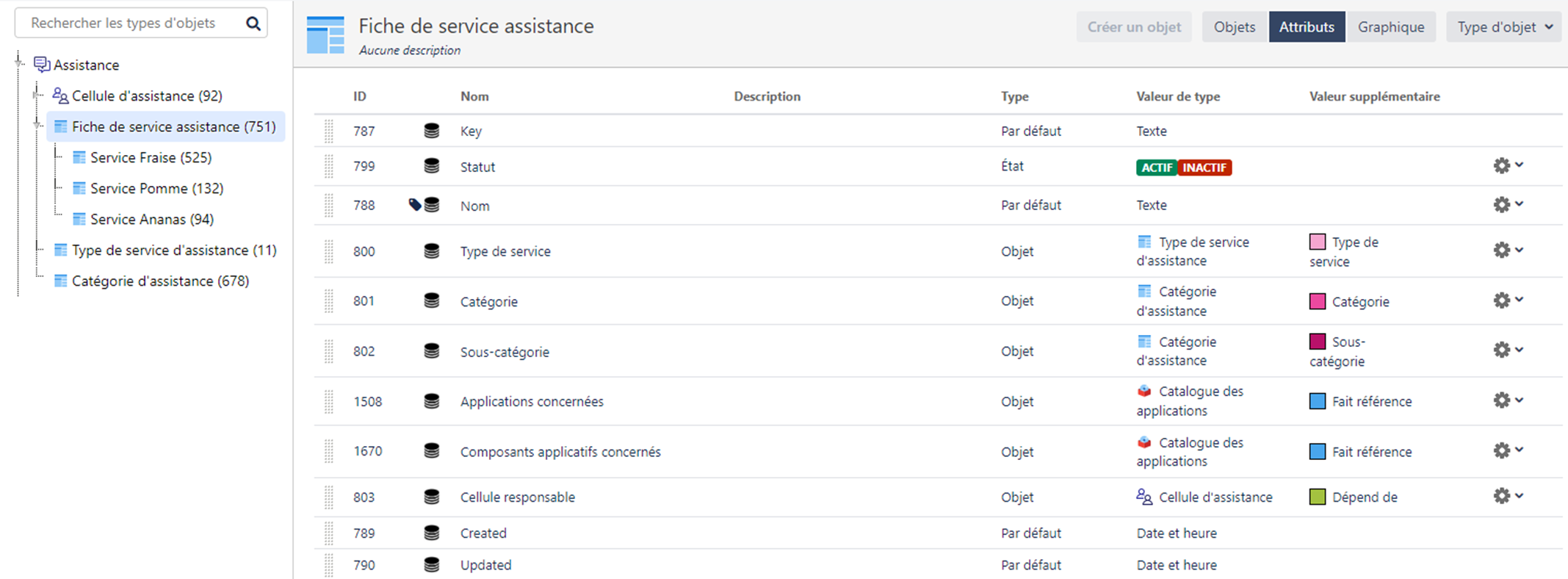
Comme pour les cellules d’assistance, nous utilisons l’héritage pour avoir une structure commune des services, mais extensible par équipe. Nous créons donc un premier type d’objet Fiche de service assistance, sous lequel nous allons décliner nos trois équipes : Service Fraise, Service Pomme et Service Ananas.
Nous avons réfléchi avec les équipes à la définition d’un service : un service est une activité proposée sur un périmètre donné. L’activité peut être de l’assistance technique, de l’assistance métier sur une application, de l’expertise métier, du traitement de données… Le périmètre peut être très varié et correspondre à un métier, une application et ses modules, ou encore une expertise.
Nous choisissons donc de travailler avec des attributs « génériques » qui pourront recouvrir toutes ces notions, sans se marcher sur les pieds ni monter une structure ultra complexe :
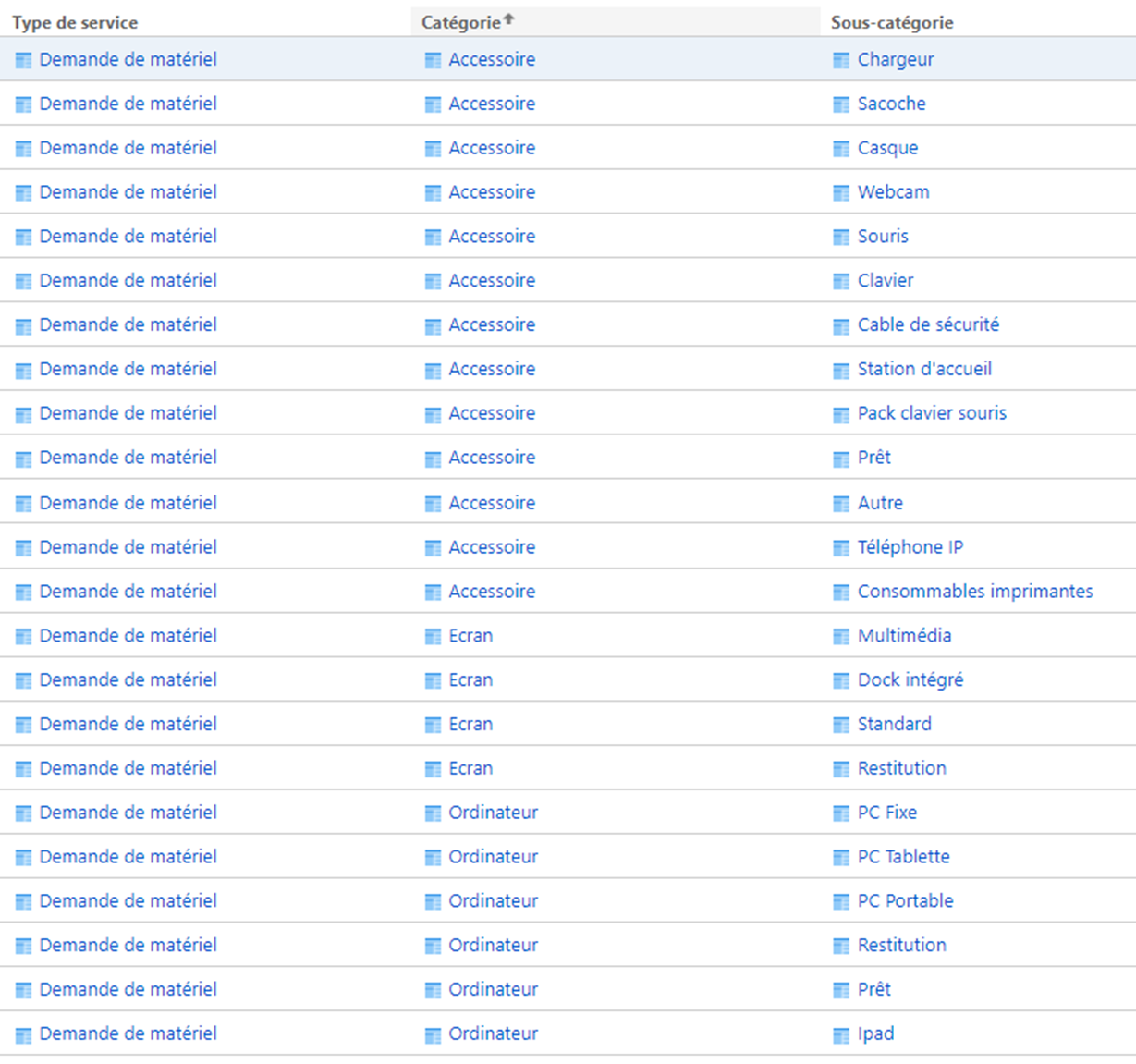
- L’activité correspond au Type de service ;
- Le périmètre est identifié grâce à deux niveaux Catégorie et Sous-catégorie.
Les catégories et sous-catégories pouvant parfois se recouper, nous choisissons de créer une liste unique commune sous forme de type d’objet regroupant toutes les valeurs possibles. Cela évite ensuite les doublons lors de recherches, exports, etc. Nous créons en complément un type d’objet pour gérer la liste des types de service.
Nous pouvons utiliser ces deux types d’objets dans nos fiches de service. Une fiche de service se décrit par :
- Un nom
- Un statut
- Un type de service
- Une catégorie
- Une sous-catégorie
- Une cellule d’assistance responsable
Le label dans Assets
Il est obligatoire pour tout type d’objet dans Assets d’avoir a minima un « label », au format texte. N’importe quel attribut au format texte peut être identifié comme étant le label de l’objet. Ce dernier peut être unique ou pas. Il est utilisé pour représenter l’objet dans les écrans, les références, certaines listes… D’où l’importance d’avoir un libellé clair et représentatif de votre objet.
Nous avons également ajouté des données supplémentaires provenant de référentiels externes, telles que l’application concernée ou impactée par le service par exemple.
Nous venons d’ajouter notre catalogue de service, c’est-à-dire l’ensemble des fiches de service des différentes équipes d’assistance. Voici le résultat obtenu :
Par exemple, voici un extrait des fiches de service des demandes de matériel :
La création des champs s’appuyant sur Assets
Avoir les données dans Assets, c’est bien. Mais pouvoir les utiliser ensuite dans les demandes d’assistance, c’est mieux ! Et pour cela, il nous faut créer et paramétrer différents champs qui seront alimentés par nos référentiels Assets.
Au préalable, il faut bien identifier les champs dont nous avons besoin :
- Un champ pour associer une cellule d’assistance à une demande ;
- Différents champs pour sélectionner les combinaisons de critères d’un service ;
- (optionnel) Un champ pour associer une fiche de service à une demande.
Remarque : nous avons fait le choix de ne pas mettre en place un champ Fiche de service, car il n’y a jusqu’à aujourd’hui aucun besoin le nécessitant. Cependant, si vous souhaitez par exemple réaliser une analyse du nombre de demandes portant sur un service donné, il sera pertinent de prévoir ce champ.
Action 3 – Création et paramétrage des champs Assets
Le premier champ mis en place est celui de la cellule d’assistance. Il s’agit d’un champ simple de type Objet Actifs. Selon le projet d’assistance (pour rappel, un projet par équipe), je dois remonter la liste des cellules d’assistance actives de l’équipe.
Pour avoir un paramétrage par projet, j’utilise la notion de « contexte de champ » de Jira. Je créé donc un contexte spécifique par projet, et pour chacun, j’ajuste le paramétrage du champ pour ne pointer que sur le type d’objet correspondant aux cellules d’assistance de mon équipe. Par exemple, dans le cas de l’équipe Pomme :

L’avantage de l’utilisation des contextes est de pouvoir personnaliser la requête selon le projet. Par exemple, l’équipe Ananas souhaite que les cellules d’assistance soient présentées par ordre de région d’intervention, et non pas par ordre alphabétique. Elle souhaite également que seules les cellules habilitées à intervenir sur le service identifié sur le ticket soient proposées :
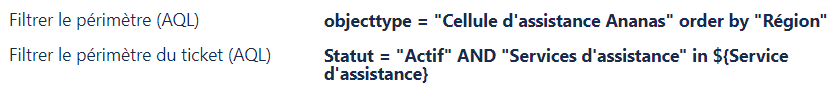
${Service d’assistance} est un pointeur vers le champ Service d’assistance que nous allons créer ci-après. Il faut imaginer que lors du chargement de la liste dans un ticket, ${Service d’assistance} sera remplacée par le label de l’objet sélectionné dans le champ Service d’assistance.
Différence entre « Filtrer le périmètre » et « Filtrer le périmètre du ticket »
Dans le premier cas, le filtre est absolu : seules les valeurs répondant au filtre seront autorisées pour le champ. Lors d’une recherche avancée sur le champ, l’auto-complétion proposera uniquement ces valeurs. Le contexte du ticket n’est pas pris en compte.
Dans le second cas, il s’agit de filtrer uniquement par rapport au contexte du ticket à l’instant T. Il est possible d’utiliser la valeur de certains champs du ticket dans le filtre.
Si vous avez des valeurs qui étaient actives et utilisées à un moment mais sont devenues obsolètes, vous souhaitez néanmoins toujours pouvoir faire des rapports ou de la recherche sur ces dernières : il est donc plus pratique de réaliser le filtre sur le statut d’un objet par exemple dans le Filtre de périmètre du ticket.
Créons maintenant les champs permettant d’identifier la fiche de service concernée par un ticket. Nous avons vu précédemment qu’un service est défini par trois critères :
- Le type de service
- Une catégorie
- Une sous-catégorie
Nous savons également que pour un type de service donné, il n’existe qu’un nombre limité de catégories disponibles. En effet, il ne serait pas cohérent de proposer toutes les catégories, sachant que seulement certaines permettent d’obtenir une combinaison gagnante pour une fiche de service. Et cela est également vrai pour les sous-catégories.
Nous devons donc créer trois champs « cascades », dont le deuxième est dépendant du premier, et le troisième dépendant du premier et du deuxième. Et la difficulté réside dans la déduction des valeurs dépendant les unes des autres. En effet, cette dépendance est portée par les fiches de service. Or, nous souhaitons remonter nos types de service et catégories, créés précédemment sous forme de types d’objets dédiés.
Nous allons donc exploiter la notion de relation entre les objets dans Assets :
- Un type de service est « valide » s’il est associé à au moins une fiche de service active ;
- Une catégorie de service est « valide » si elle est associée à au moins une fiche de service active dont le type de service est celui sélectionné préalablement ;
- Une sous-catégorie de service est « valide» si elle est associée à au moins une fiche de service active dont le type de service et la catégorie sont ceux sélectionnés préalablement.
Grâce à la fonction proposée par Assets inboundReferences() (inR() en abrégé), il est possible de rechercher tous les objets ayant une relation entrante depuis un objet répondant à certains critères. Vous pouvez trouver d’autres exemples et plus d’information sur la recherche dans Assets dans la documentation de l’éditeur (en anglais) : Advanced searching: AQL – Assets Query Language.
Voici un exemple de la configuration des trois champs pour l’équipe Fraise :



Pourquoi ne pas utiliser les champs Assets « référencés » ?
Assets met à disposition un type de champ personnalisé Objet Actifs référencé qui permet d’avoir directement une dépendance avec un autre champ Objet Actifs simple.
Les champs référencés de Assets amènent plusieurs limitations et ne nous ont pas convaincus :
- Il faut choisir dès la création du champ si ce dernier est à sélection multiple ou unique, contrairement au champ Objet Actifs qui permet de modifier ce paramétrage à la volée et selon les contextes ;
- La dépendance n’existe que sur un niveau : il n’est pas possible d’avoir un champ référencé dépendant d’un autre champ référencé.
Cependant, à noter que l’utilisation de champs simples Objet Actifs induit une contrainte non négligeable : lorsque la valeur d’un champ parent est modifiée, les champs dépendants ne sont pas réinitialisés. Il est donc possible, si cela n’est pas géré autrement, d’avoir des incohérences dans la sélection des valeurs. Il s’agit d’une anomalie identifiée chez l’éditeur, mais pour le moment non corrigée.
Ce problème peut être contourné à l’aide d’un simple script de type Behaviour du plugin Script Runner par exemple. Vous pouvez consulter la documentation de l’éditeur (en anglais) pour en savoir plus.
Nous avons donc maintenant à notre disposition toutes les données dont nous avons besoin pour mettre en place notre orientation automatique. 🙌

Et maintenant… que vais-je faire ? 🎶
Bon, je ne vous cache pas que nous avons fait la partie la plus facile… Et il est temps de faire une pause.
Dans le prochain article, nous nous attaquerons à ce pourquoi nous avons fait tout ça : la mise en place de tous les éléments permettant d’automatiser l’orientation des demandes vers la bonne cellule d’assistance. Attention, ce sera beaucoup plus technique.
Nous en profiterons également pour étendre un peu la réflexion et voir comment aller plus loin avec des référentiels complémentaires, des files d’attente bien configurées, etc.
Illustration de couverture par pch.vector sur Freepik